
Как скачать сайт как приложение
Обновлено: 17.05.2024
Можно ли скопировать любой сайт в интернете? Да, конечно. Для этого потребуется всего пара минут и несколько кликов. Но с одной оговоркой - вы получите его html-код, внешний вид сайта, без сложных скриптов (для их реализации потребуется программист). Этот вариант подойдет для тех, кому нужно скопировать несложный сайт - например, лендинг конкурента и быстро запустить рекламу.
Скопировать сайт целиком и переделать?
Стоит понимать, что, копируя сайт, вы с большой вероятностью столкнетесь с “сюрпризами”, которые обязательно нужно проверить перед работой:
- корректная верстка (все элементы на своих местах, работает исправно и мобильная версия, и десктоп),
- все картинки загружаются (при копировании, возможно, что-то не сохранилось, неправильно указан путь файла в коде),
- активные элементы работают исправно (кнопки, формы).
Все эти мелочи исправляются за несколько минут самостоятельно, либо с помощью фрилансеров, если речь идет о скриптах.
Для самостоятельной работы с кодом рекомендуем: Sublime Text, Visual Studio Code, Atom.
Далее, все что вам останется - перенести сайт на ваш хостинг с доменом.
Так чем же скопировать сайт?
7 способов бесплатно скопировать сайт
Самый простой способ: “Ctrl+S” - команда в браузере, которая сохраняет текущую страницу. Быстро, без посторонних сервисов, но с высокой вероятностью потерять часть сайта (динамические элементы, скрипт, формы) - больше подойдет для копирования контента страниц.
Если вам нужно скопировать работоспособный одностраничный сайт, то лучше обратиться к специальным сервисам, которые помимо HTML, копируют CSS, JavaScript, все изображения, анимации, ссылки и формы. Тем более, что часть из них полностью бесплатна.
Web2zip

Сервис копирует HTML, CSS, JavaScript, изображения и шрифты.
Saveweb2zip

При скачивании есть возможность автоматически переименовать названия файлов, скопировать мобильную версию сайта.
CopySite

Стоимость - 300 руб./мес., 200 руб./неделя, 75 руб./сутки.
Web ScrapBook
Web ScrapBook - бесплатное браузерное расширение, которое позволяет скачивать необходимые страницы сайта не покидая целевую страницу.

Сервис имеет широкий опционал для настройки, позволяющий работать с мультимедийными файлами и скриптами: скачивать, вырезать, заменять, пропускать.

Httrack
Httrack - бесплатный локальный сервис, для работы нужно устанавливать на компьютер. С задачей справляется отлично, основное преимущество - можно скачивать несколько сайтов одновременно (списком загружать url), всегда готов к работе (не зависит от работоспособности онлайн-сервисов), менее удобен, чем решения выше.
Cyotek WebCopy
Cyotek WebCopy - один из сервисов компании Cyotek, требует установки, но абсолютно бесплатный. Копирует контент, а также стили, но теряет JavaScript.
Отлично подойдет для парсинга контента сайтов и копировании простых сайтов.
Параметры отвечают за:
- -r — указывает на то, что нужно переходить по ссылкам на сайте, чтобы скачивать все подкаталоги и все файлы в подкаталогах.
- -k — преобразует все ссылки в скаченных файлах, чтобы по ним можно было переходить на локальном компьютере в автономном режиме.
- -p — указывает на то, что нужно загрузить все файлы, которые требуются для отображения страниц (изображения, css и т.д.).
- -l — определяет максимальную глубину вложенности страниц, которые нужно скачать. Обычно сайты имеют страницы с большой степенью вложенности и чтобы wget не начал «закапываться», скачивая страницы, можно использовать этот параметр.
- -E — добавлять к загруженным файлам расширение .html.
- -nc — указывает на то, что существующие файлы не будут перезаписаны - например, при продолжении ранее прерванной загрузки сайта.
Среди платных решений стоит выделить также: RoboTools (2$ - 250 стр), Teleport Pro ($50).
Если вам нужен качественный сайт или его копия, то рекомендуем все же обратиться к специалистам - тогда значительно повысится вероятность, что все элементы будут корректно работать, сайт - выполнять свою задачу, а трафик - приносить вам деньги.
Чтобы не было сюрпризов, обязательно проверяйте работоспособность сайта перед работой со всех устройств!
Всем доброго дня!
Однако, в некоторых случаях это может быть очень полезно:

Чем загрузить сайты к себе на жесткий диск // зеркало ресурса
HTTrack
Несмотря на свой архаичный интерфейс, программа одна из лучших в своем сегменте. Для начала создания полной копии сайта ("зеркала") — вам достаточно ее запустить, указать папку на HDD, и нажать "Старт" .
Делаем бэкап сайта
HTTrack скачивает все веб-странички указанного ресурса на жесткий диск ПК, вместе с изображениями и большинством скриптов.

Отдельно отмечу, что HTTrack может периодически проверять нужный сайт и до-загружать, если на нем появилось что-то новенькое. Программа поддерживает русский и работает на Windows, Linux и Android.
Cyotek WebCopy
Cyotek WebCopy — еще один достойный инструмент для создания зеркальных копий веб-сайтов. Программа не поддерживает русский, зато она полностью бесплатная.
Пользоваться ей крайне просто: достаточно указать URL-адрес сайта, папку (Folder) и нажать кнопку "Copy" .

WebCopy — скрин главного окна
Через определенное время сайт будет загружен и его можно будет использовать без доступа к интернету. Кстати, у WebCopy есть достаточно большое количество фильтров — это дает возможность, например, загружать не весь сайт целиком, а только определенную его часть.

Процесс работы с офлайн-версией очень прост — достаточно выбрать нужную веб-страничку в нижней части окна и нажать на "Open in Browser" .

Открыть локальную папку
Website Extractor
Сразу скажу, что эта программа платная (но с пробным периодом). Она существенно отличается от вышеприведенных: как функционально, так и дизайном.

Website Extractor — главное окно
Добавлю, что Website Extractor имеет десятки различных надстроек, фильтров, лимитов и т.д. и т.п. (что делает программу намного гибче и многофункциональнее вышеприведенных продуктов).
Вообще, Website Extractor больше подходит опытным пользователям (нежели новичкам).
Local Website Archive
Local Website Archive — весьма добротная программа для быстрого создания зеркала веб-сайтов (есть как платная, так и бесплатная версии).
Основное ее отличие от других в том, что у нее есть портативная версия (которую не нужно устанавливать) , что очень удобно — можно взять на флешке с собой и запускать на любом ПК.

Local Website Archive — главная страничка сайта
Отмечу, что эта программа тесно интегрируется с Internet Explorer, может сохранять странички в PDF, имеет поддержку русского языка, фильтров и десятки настроек.
Интерфейс Local Website Archive крайне прост: слева - панель закладок, справа - основное окно со списком веб-страничек. Пользоваться программой легко и удобно (аналогично вышеприведенным). Рекомендую к знакомству!
На сим пока всё. Дополнения по теме — будут кстати!


Подскажите, пожалуйста, насколько глубоко проникновение подобных программ в сайт при скачивании?
Я имею в виду, если на моем сайте есть запароленные страницы, или страницы в черновиках, или устаревшие страницы (которые я убрал из общего доступа т.к. обнаружил в них ошибки), но не удалил с сайта т.к.в них есть правильный и нужный мне материал (который я собираюсь в последствии переработать с учетом выявленных ошибок).
Скачает ли их какая-нибудь из рассмотренных вами программ?
Выкачает ли базу данных с картинками? Сможет ли скачивающий получить доступ ко всей структуре сайта?
К тем материалам, которые я пока не хотел бы афишировать и держу, как в записной книжке, только для себя или только готовлю к публикации, и не желаю преждевременной утечки?
Доброго времени.
Программы загрузят только то, что есть в открытом доступе на сайте. Те данные, которые доступны только после регистрации и авторизации — разумеется, не загрузятся.


БЕЗ скриптов, макросов, регулярных выражений и командной строки.
Эта статья пригодится студентам, которые хотят скачать все картинки с сайта разом, чтобы потом одним движением вставить их в Power Point и сразу получить готовую презентацию. Владельцам электронных библиотек, которые собирают новые книги по ресурсам конкурентов. Просто людям, которые хотят сохранить интересный сайт/страницу в соцсети, опасаясь, что те могут скоро исчезнуть, а также менеджерам, собирающим базы контактов для рассылок.
Есть три основные цели извлечения/сохранения данных с сайта на свой компьютер:
- Чтобы не пропали;
- Чтобы использовать чужие картинки, видео, музыку, книги в своих проектах (от школьной презентации до полноценного веб-сайта);
- Чтобы искать на сайте информацию средствами Spotlight, когда Google не справляется (к примеру поиск изображений по exif-данным или музыки по исполнителю).
Ситуации, когда неожиданно понадобится автоматизированно сохранить какую-ту информацию с сайта, могут случиться с каждым и надо быть к ним готовым. Если вы умеете писать скрипты для работы с утилитами wget/curl, то можете смело закрывать эту статью. А если нет, то сейчас вы узнаете о самых простых приемах сохранения/извлечения данных с сайтов.
1. Скачиваем сайт целиком для просмотра оффлайн
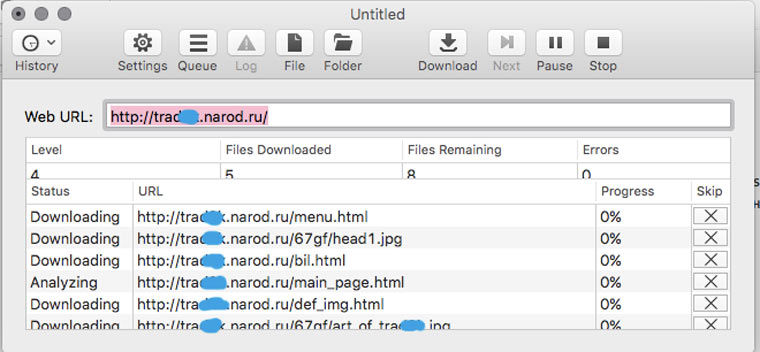
В OS X это можно сделать с помощью приложения HTTrack Website Copier, которая настраивается схожим образом.
Пользоваться Site Sucker очень просто. Открываем программу, выбираем пункт меню File -> New, указываем URL сайта, нажимаем кнопку Download и дожидаемся окончания скачивания.
2. Прикидываем сколько на сайте страниц
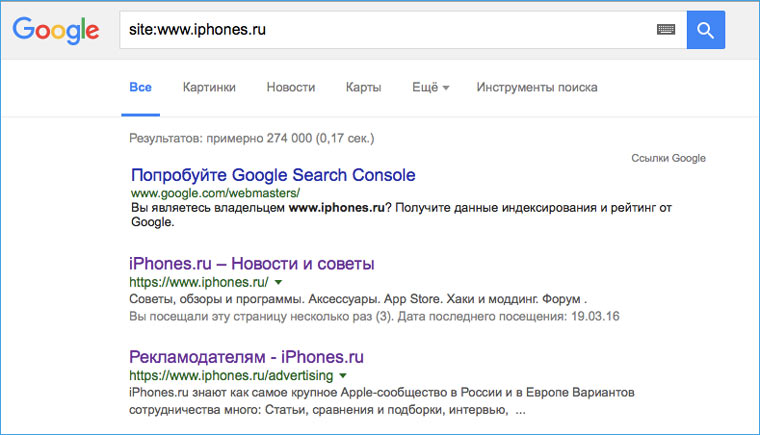
Перед тем как браться за скачивание сайта, необходимо приблизительно оценить его размер (не затянется ли процесс на долгие часы). Это можно сделать с помощью Google. Открываем поисковик и набираем команду site: адрес искомого сайта. После этого нам будет известно количество проиндексированных страниц. Эта цифра не соответствуют точному количеству страниц сайта, но она указывает на его порядок (сотни? тысячи? сотни тысяч?).
3. Устанавливаем ограничения на скачивание страниц сайта
![]()
Если вы обнаружили, что на сайте тысячи страниц, то можно ограничить число уровней глубины скачивания. К примеру, скачивать только те страницы, на которые есть ссылка с главной (уровень 2). Также можно ограничить размер загружаемых файлов, на случай, если владелец хранит на своем ресурсе tiff-файлы по 200 Мб и дистрибутивы Linux (и такое случается).
Сделать это можно в Settings -> Limits.
4. Скачиваем с сайта файлы определенного типа
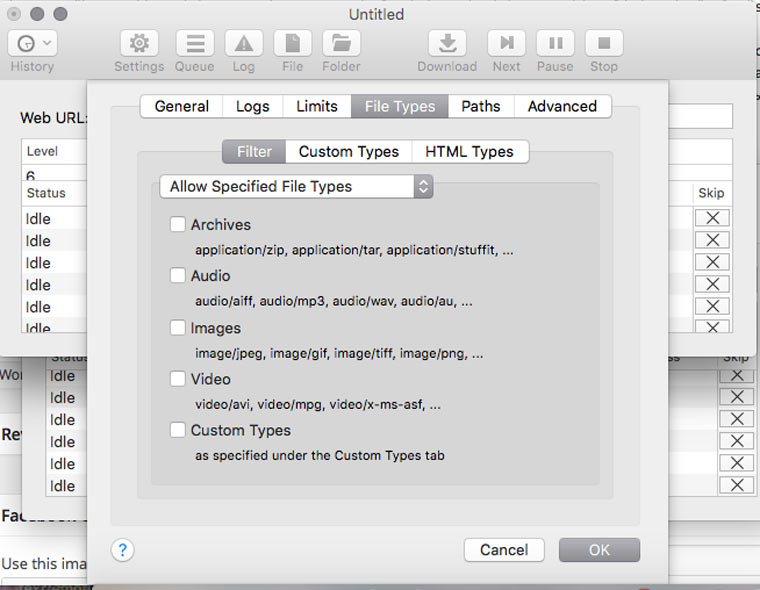
В Settings -> File Types -> Filters можно указать какие типы файлов разрешено скачивать, либо какие типы файлов запрещено скачивать (Allow Specified Filetypes/Disallow Specifies Filetypes). Таким образом можно извлечь все картинки с сайта (либо наоборот игнорировать их, чтобы места на диске не занимали), а также видео, аудио, архивы и десятки других типов файлов (они доступны в блоке Custom Types) от документов MS Word до скриптов на Perl.
5. Скачиваем только определенные папки
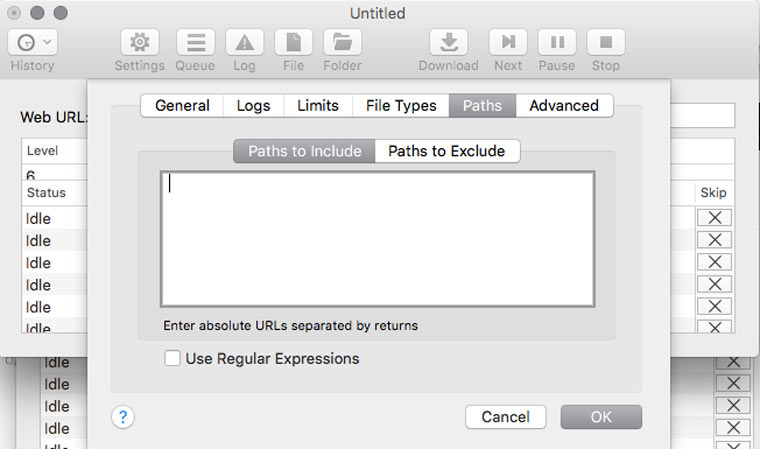
Если на сайте есть книги, чертежи, карты и прочие уникальные и полезные материалы, то они, как правило, лежат в отдельном каталоге (его можно отследить через адресную строку браузера) и можно настроить SiteSucker так, чтобы скачивать только его. Это делается в Settings -> Paths -> Paths to Include. А если вы хотите наоборот, запретить скачивание каких-то папок, то их адреса надо указать в блоке Paths to Exclude
6. Решаем вопрос с кодировкой
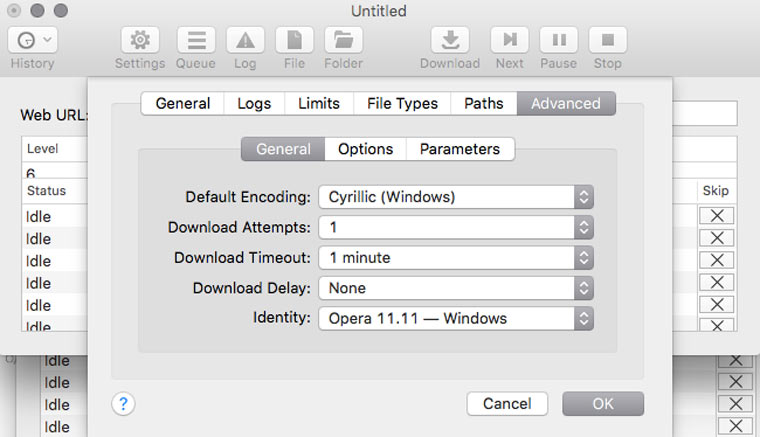
Если вы обнаружили, что скачанные страницы вместо текста содержат кракозябры, там можно попробовать решить эту проблему, поменяв кодировку в Settings -> Advanced -> General. Если неполадки возникли с русским сайтом, то скорее всего нужно указать кодировку Cyrillic Windows. Если это не сработает, то попробуйте найти искомую кодировку с помощью декодера Лебедева (в него надо вставлять текст с отображающихся криво веб-страниц).
7. Делаем снимок веб-страницы
Это может пригодиться для сравнения разных версий дизайна сайта, запечатления на память длинных эпичных перепалок в комментариях или в качестве альтернативы способу сохранения сайтов, описанного в предыдущих шести пунктах.
8. Сохраняем картинки только с определенной страницы
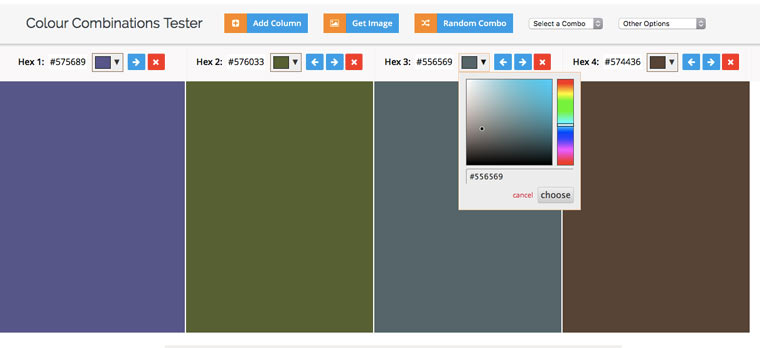
9. Извлекаем HEX-коды цветов с веб-сайта
10. Извлекаем из текста адреса электронной почты
11. Извлекаем из текста номера телефонов
А если надо отфильтровать в тексте заголовки, даты и прочую информацию, то к вам на помощь придут регулярные выражения и Sublime Text.
(2 голосов, общий рейтинг: 4.50 из 5)
БЕЗ скриптов, макросов, регулярных выражений и командной строки.
Эта статья пригодится студентам, которые хотят скачать все картинки с сайта разом, чтобы потом одним движением вставить их в Power Point и сразу получить готовую презентацию. Владельцам электронных библиотек, которые собирают новые книги по ресурсам конкурентов. Просто людям, которые хотят сохранить интересный сайт/страницу в соцсети, опасаясь, что те могут скоро исчезнуть, а также менеджерам, собирающим базы контактов для рассылок.
Есть три основные цели извлечения/сохранения данных с сайта на свой компьютер:
- Чтобы не пропали;
- Чтобы использовать чужие картинки, видео, музыку, книги в своих проектах (от школьной презентации до полноценного веб-сайта);
- Чтобы искать на сайте информацию средствами Spotlight, когда Google не справляется (к примеру поиск изображений по exif-данным или музыки по исполнителю).
Ситуации, когда неожиданно понадобится автоматизированно сохранить какую-ту информацию с сайта, могут случиться с каждым и надо быть к ним готовым. Если вы умеете писать скрипты для работы с утилитами wget/curl, то можете смело закрывать эту статью. А если нет, то сейчас вы узнаете о самых простых приемах сохранения/извлечения данных с сайтов.
1. Скачиваем сайт целиком для просмотра оффлайн
В OS X это можно сделать с помощью приложения HTTrack Website Copier, которая настраивается схожим образом.
Пользоваться Site Sucker очень просто. Открываем программу, выбираем пункт меню File -> New, указываем URL сайта, нажимаем кнопку Download и дожидаемся окончания скачивания.
2. Прикидываем сколько на сайте страниц
Перед тем как браться за скачивание сайта, необходимо приблизительно оценить его размер (не затянется ли процесс на долгие часы). Это можно сделать с помощью Google. Открываем поисковик и набираем команду site: адрес искомого сайта. После этого нам будет известно количество проиндексированных страниц. Эта цифра не соответствуют точному количеству страниц сайта, но она указывает на его порядок (сотни? тысячи? сотни тысяч?).
3. Устанавливаем ограничения на скачивание страниц сайта
![]()
Если вы обнаружили, что на сайте тысячи страниц, то можно ограничить число уровней глубины скачивания. К примеру, скачивать только те страницы, на которые есть ссылка с главной (уровень 2). Также можно ограничить размер загружаемых файлов, на случай, если владелец хранит на своем ресурсе tiff-файлы по 200 Мб и дистрибутивы Linux (и такое случается).
Сделать это можно в Settings -> Limits.
4. Скачиваем с сайта файлы определенного типа
В Settings -> File Types -> Filters можно указать какие типы файлов разрешено скачивать, либо какие типы файлов запрещено скачивать (Allow Specified Filetypes/Disallow Specifies Filetypes). Таким образом можно извлечь все картинки с сайта (либо наоборот игнорировать их, чтобы места на диске не занимали), а также видео, аудио, архивы и десятки других типов файлов (они доступны в блоке Custom Types) от документов MS Word до скриптов на Perl.
5. Скачиваем только определенные папки
Если на сайте есть книги, чертежи, карты и прочие уникальные и полезные материалы, то они, как правило, лежат в отдельном каталоге (его можно отследить через адресную строку браузера) и можно настроить SiteSucker так, чтобы скачивать только его. Это делается в Settings -> Paths -> Paths to Include. А если вы хотите наоборот, запретить скачивание каких-то папок, то их адреса надо указать в блоке Paths to Exclude
6. Решаем вопрос с кодировкой
Если вы обнаружили, что скачанные страницы вместо текста содержат кракозябры, там можно попробовать решить эту проблему, поменяв кодировку в Settings -> Advanced -> General. Если неполадки возникли с русским сайтом, то скорее всего нужно указать кодировку Cyrillic Windows. Если это не сработает, то попробуйте найти искомую кодировку с помощью декодера Лебедева (в него надо вставлять текст с отображающихся криво веб-страниц).
7. Делаем снимок веб-страницы
Это может пригодиться для сравнения разных версий дизайна сайта, запечатления на память длинных эпичных перепалок в комментариях или в качестве альтернативы способу сохранения сайтов, описанного в предыдущих шести пунктах.
8. Сохраняем картинки только с определенной страницы
9. Извлекаем HEX-коды цветов с веб-сайта
10. Извлекаем из текста адреса электронной почты
11. Извлекаем из текста номера телефонов
А если надо отфильтровать в тексте заголовки, даты и прочую информацию, то к вам на помощь придут регулярные выражения и Sublime Text.
(2 голосов, общий рейтинг: 4.50 из 5)
Читайте также: